Getting started with AI models that learn through sequences instead of step-by-step feedback changes how you think about training agents. The Decision Transformer doesn’t follow the usual reinforcement learning process. It doesn’t rely on trial-and-error updates during training. Instead, it learns from fixed logs of experience, using a goal-driven approach to predict the next best action.
That gives it the flexibility to use existing datasets without needing direct access to the environment. If you're familiar with transformers in language models, the structure here will feel somewhat similar. This guide walks you through how to train your first Decision Transformer from the ground up.
What is a Decision Transformer?
The Decision Transformer treats reinforcement learning as a sequence modelling task. Instead of learning through real-time feedback, it predicts actions by analyzing patterns in past behaviour. It uses sequences of state, action, and return-to-go as inputs and then learns to predict the next action based on this context.

Return-to-go represents the total expected reward from a certain point onward. By conditioning on return-to-go, the model can be directed toward higher- or lower-performing trajectories during both training and inference. This is especially useful in offline reinforcement learning, where the model is trained using a static dataset of past experiences rather than collecting new ones through interaction.
The structure resembles how transformers in NLP operate. Rather than processing words in a sentence, it processes state-action-return triplets. These are embedded and passed through transformer layers, just like tokens in a language model. The result is a flexible model that can learn complex behaviours and even adapt to different goals at test time by adjusting the return-to-go input.
How to Set Up Your Environment and Dataset?
Before you begin training, you need a dataset. Decision Transformers rely on pre-collected data instead of live interaction. D4RL (Datasets for Deep Data-Driven Reinforcement Learning) is a popular source. It includes data from environments like Mujoco and Atari, collected using different strategies—some with expert policies, others more random or mixed.
Each entry in the dataset includes:
- State: the observation of the environment at a given time.
- Action: what the agent did in that state.
- Reward: the payoff received after the action.
- Done: a flag marking the end of an episode.
- Return-to-go: the future total reward starting from that step.
These sequences are used to train the model. You'll need Python with libraries such as PyTorch or JAX for modelling. For environments and data loading, use Gym and D4RL. Input sequences are formatted similarly to language models, where the goal is to predict the next action given previous steps and a return target.
For example:
(Rt, St, At, Rt+1, St+1, At+1, ...)
Each element is embedded into a fixed-size vector. These vectors are passed through transformer blocks, and the model learns to predict the next action token. Unlike traditional reinforcement learning, this method doesn’t require constant evaluation of value functions or policy gradients. It simplifies training, especially for those with experience in supervised learning.
Training Your Decision Transformer
The training follows a supervised learning setup. Given a sequence of past state-action-return pairs, the model is trained to predict the next action using mean squared error loss. Since most environments use continuous actions, this loss is a natural fit.
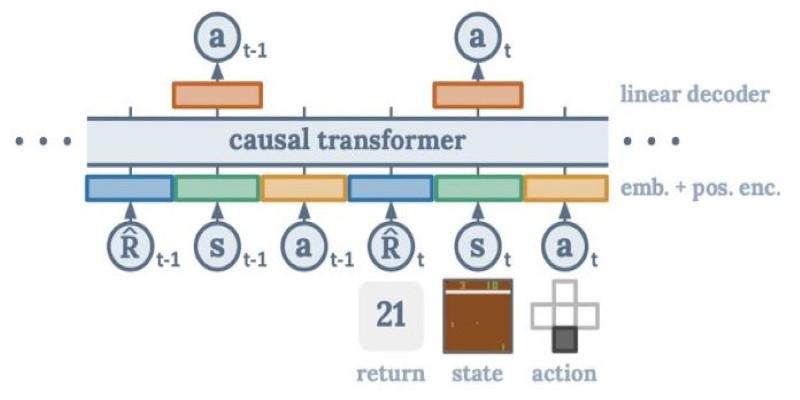
The architecture itself is a transformer encoder, much like the one used in models like BERT. Each input—state, action, return—is separately embedded, combined with positional encodings, and fed into multiple layers of attention and feedforward networks.
A typical training loop includes:
- Sampling sequences from the dataset.
- Embedding each element and adding positional information.
- Feeding the sequence through the transformer.
- Predicting the next action and comparing it to the actual action.
- Backpropagating the loss and updating the weights.
Learning rate scheduling, dropout, and batch size tuning help stabilize training. The model usually benefits from a warm-up phase and weight decay to prevent overfitting. State and return normalization are also key for good performance.
The training process is relatively efficient compared to traditional reinforcement learning, as it's offline and doesn't require repeated rollouts. You can iterate more quickly and test ideas without resetting environments or waiting for simulations to finish.
Testing and Improving Performance
Testing involves running the trained model in an environment to see if it can achieve a specific return. You start with an initial state and a return-to-go target, then let the model predict actions step by step. At each time step, you feed the new state and updated return back into the model, forming a loop until the episode ends.
If the model consistently achieves returns close to the target, it’s doing well. If it falls short, you may need to improve training data quality or model settings. Models trained on high-performing trajectories usually generalize better. On the other hand, training on inconsistent or poor data can limit how well the model learns good behaviour.
To improve performance:
- Vary sequence lengths to give the model a broader context.
- Use more diverse or expert-level datasets.
- Adjust return conditioning to encourage generalization.
- Tune transformer hyperparameters, such as depth and attention heads.
Another benefit of return conditioning is the ability to control the model's behaviour at runtime. You can push it toward more aggressive or conservative strategies just by changing the return-to-go input. This flexibility is useful in safety-sensitive or resource-constrained applications where different outcomes are preferred at different times.
Conclusion
Training a Decision Transformer offers a different way to build intelligent agents. Instead of relying on live feedback or exploration, it learns from existing datasets, making it suitable for settings where real-time interaction is limited or expensive. By using sequence models, it captures long-term patterns in behaviour, leading to more consistent and goal-directed decision-making. For anyone with experience in supervised learning or language models, the transition is smooth. The architecture and training process mirror familiar techniques. With quality data, a well-tuned model, and return-based conditioning, you can build agents that generalize well and follow desired goals—all without constant environmental feedback. It's a grounded, data-driven approach to agent training.











